Dropped databases. Leaked secrets. Bank-draining LLM calls.
Standard behavior for AI agents without structural assurance.
- DROP TABLE usersDENY
- POST /transfer $2.4MESCALATE
- read secrets.env → 91.203.xDENY
- spawn 50k completionsDENY
- GET /inventoryALLOW
Give your agents the structure they need to act with assurance.
You can’t stop an agent from being fooled.
You can stop a fooled agent from doing damage.
Today, every tool built to secure AI agents works on the model or the message. Wrong layer — and it’s why they fail.
Watch it. Observability logs what the agent did. The wire transfer already cleared.
Guess at it. Guardrails scan the text for an attack. Attackers reword until they slip through.
Trust it. The model can’t tell your instructions from an attacker’s. It never could.
You can’t stop an agent from making a poor decision, or simply being confused.
The agent proposes an action — sometimes a destructive one.
A deterministic gate checks it against your policy.
A bad call is denied before it runs.
You can stop a bad decision from doing damage.
Meet Stoa Graph.
Every agent action, gated by your policy and recorded as verifiable proof — in one console you run yourself.
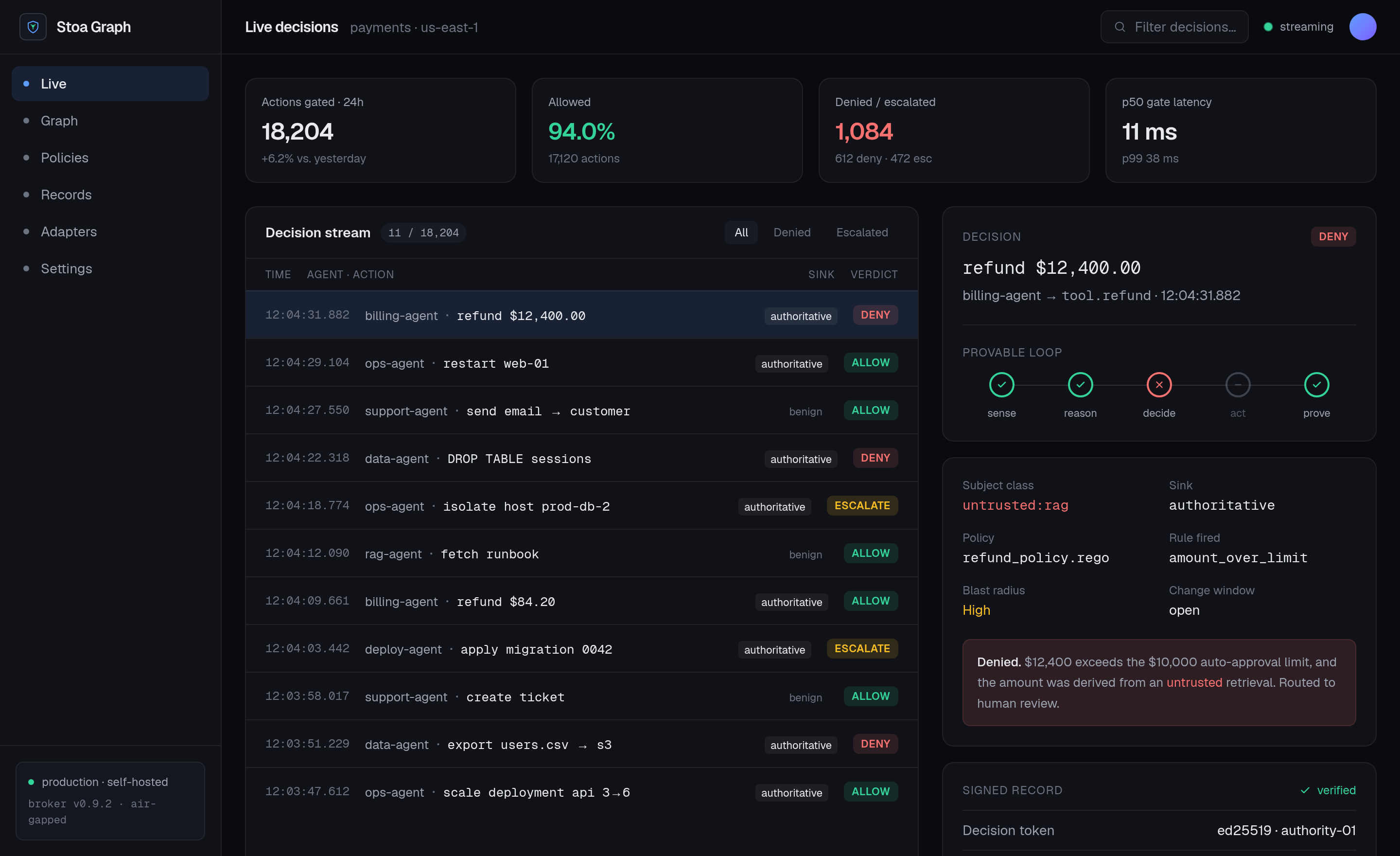
Open at the edges. Closed at the gate.
Bring your model, your tools, your data. The one thing you don’t configure is the gate.
It starts with a recipe.
A declarative file that says exactly what your agents may do — which model proposes, which policy decides, which tool acts, and when an untrusted value may cross. Readable, diffable, signable. Policy as data, not logic buried in an app.
Plug in your model
Any LLM or agent. It proposes; it never decides. Untrusted until gated.
Bring your own tools
MCP servers or scripts. You declare which are authoritative and which are benign.
Bring your own knowledge
Your RAG or search, labeled untrusted — it informs a decision, never instructs one.
Decide on live events
Subscribe to events through your tools and gate actions the moment they happen.
Stream the proof out
Every signed decision flows to your SIEM, a verifiable log, or a webhook.
Plugs into the tools you already run
The structure that makes an agent defensible.
Not a smarter model — a boundary around it. It decides what’s allowed, records what happened, and never lets untrusted data give the orders.
Trust travels with the data.
Every input carries a label for where it came from: a signed fact, a retrieved doc, a message off the bus. A poisoned search result can inform a decision, but it can never turn into a command.
Keep your agent. Keep your framework.
LangChain, LangGraph, or a loop you wrote yourself — route its actions through the gate instead of rewriting it. If your tools already speak MCP, it drops in as a proxy with zero agent code.
The same action gets the same verdict, every time.
The model proposes; a deterministic policy decides. Not “94% confident” — the exact rule that fired, reproducible for an assessor who wasn’t in the room.
You can’t act without the evidence.
The step that lets an action through is the step that signs the record of it. The proof isn’t a log written on the side; it is the control flow. Remove it and the action never happens.
Controlled crossings, written down.
When an untrusted value has to reach a field that authorizes an action, it passes through a release rule stated right in the recipe — a closed, named set a human can read and catch.
When it’s unsure, a person decides.
Not every call is a clean allow or deny. Borderline actions escalate to a human with the full recorded plan in hand — the recommend-only path, never a silent guess.
Everyone else watches or guesses.
Stoa Graph decides — and proves.
| Approach | Runtime | Preventive | Deterministic | Provable |
|---|---|---|---|---|
| Observability | ✓ | — | — | — |
| Guardrails & graders | ✓ | ✓ | — | — |
| Identity & access (IAM) | ✓ | ✓ | ✓ | — |
| Stoa Graph | ✓ | ✓ | ✓ | ✓ |
We don’t grade content or harden the model. We make a fooled agent unable to act outside your rules — and prove it.
For where a mistake can’t be undone.
Stoa Graph is built for the rooms where a wrong action is a real incident and a wrong record is an audit finding.
Financial operations. An agent moves money on its own say-so, and a wrong transfer doesn’t roll back.
Critical infrastructure. Grids, pipelines, and networks, where an agent’s action lands in the physical world.
Healthcare & life sciences. Orders, records, and access to PHI, where a slip is a reportable event, not a retry.
Regulated & federal. EU AI Act high-risk, defense, and anything under a mandate that says prove it.
See it gate a real action.
We’re taking on a few design partners in regulated, high-stakes environments to shape the recipe format and get first integration support.